一个$m×n$的矩阵就是$m×n$个数排成$m$行$n$列的一个数阵. 矩阵可以用于批量解决一些线性问题,例如递推方程.
另,$1\times m$的矩阵又叫做向量
啥是矩阵乘法
蒟阵乘法,顾名思义,就是两个矩阵(蒟蒻)乘起来,不过和普通的乘法不一样.
A.两个矩阵能相乘的条件
当一个矩阵的行数等于另一个矩阵的列数时,两个相乘才有意义.
B.矩阵咋相乘
三个矩阵$a,b,c$
如果$a$等于$bc$的乘积,那么写作$a=bc$
假设$b,c$都是$n\times n$的矩阵,那么有
写成矩阵的形式就是
这也就是为什么必须要求一个矩阵的行数等于另一个矩阵的列数,否则元素数不相等
C.注意事项
如果两个大小为$a\times n,n\times m$的矩阵相乘,最后乘出来的矩阵就是是$a\times m$的
而矩阵乘法的次数就是$a\times n\times m$
例如$2\times 3$和$3\times 2$的矩阵相乘
如果问原因的话,我们可以发现,新矩阵的行数和左边矩阵的行数相等,而新矩阵的列数和后边矩阵的列数相等.
D.这东西有啥性质啊
- 矩阵乘法满足结合律,即$a(bc)=(ab)c$,可以通过这个性质减少乘法次数
- 而且,矩阵乘法没有交换律
因为普通的加法和乘法满足交换律的原因是因为加法和乘法的结果都只是一个数,而矩阵的本质是数的排列,所以运算结果还是矩阵,并不是一个数,自然和数有区别 矩阵的单位元…~~这东西也不知道放在哪,就写这吧. ~~
$\left[\begin{array}{lll}{1} & {0} & {0} \\\\ {0} & {1} & {0} \\\\ {0} & {0} & {1}\end{array}\right]$就是对角线上全为1
这玩意有啥用
我咋知道啊
在某些题中可以加速递推公式,可以把一个$O(n)$的式子优化到$O(logn)$
应用前提:矩阵快速幂(这又是啥啊)
因为矩阵的乘法也有结合律,所以也可以用快速幂加速,也是矩阵优化递推的原理,即把一个不能用快速幂优化的式子转换成快速幂的形式
来个栗子啊
出门左转炒锅
请你求出$f(n)\mod10^9+7$的值($n$在$longlong$($INT64$)范围内).
显然线性爆炸,所以考虑加速. 那么很容易想到矩阵乘法(我也不会别的)
那么考虑把这个递推式子变成可以矩阵的形式,那么就考虑把答案弄进一个矩阵里,(那么就设一个$1\times 1$的吧!(啪))
显然,设一个$1\times 1$的矩阵是一个很不明智的行为,因为没法转移. 考虑到当前的状态与前两项有关.
所以构造一个$1\times 2$向量表示$\begin{bmatrix}F_n & F_{n-1}\end{bmatrix}$
那么转移也就很显然了
我们要达到这样一个目的:
变个形
那么就可以构造中间的矩阵了
显然就是
带回去验证一下$qwq$
发现成立了诶.
更大的栗子
出门右转大炒锅
广义的斐波那契数列是指形如$a_n=p\times a_{n-1}+q\times a_{n-2}$的式子,给出$p,q,a_1,a_2,n,m$,求$a_n\mod m$.
除了和上一题的系数不变没区别啊喂(#`O′)(啪,多嘴)
考虑到只有转移时的系数变了,那么只要改变你构造的矩阵就可以了,那么我们再考虑转移是如何进行的
那么注意到改变的实际上只有这一项$F_{n-1}\times 1+F_n\times 1$,考虑这一项是怎么来的,根据矩阵乘法的定义我们知道这一项实际上是
向量的第一行乘矩阵的第一列,也就是$\begin{bmatrix}F_n & F_{n-1}\end{bmatrix}\begin{bmatrix}1 \\\\ 1\end{bmatrix}$
那么我们只需要改动这一列即可,即把这一列改为$\begin{bmatrix}p \\\\ q\end{bmatrix}$
那么最后的转移矩阵就是
最后放上这个题的核心代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| ll mod;
struct mar
{
ll a[4][4];
}ans,base;
mar mul(mar x,mar y)
{
mar t;
memset(t.a,0,sizeof(t.a));
for(int i=1;i<=2;++i)
for(int j=1;j<=2;++j)
for(int k=1;k<=2;++k)
t.a[i][j]+=(x.a[i][k])%mod*(y.a[k][j])%mod,t.a[i][j]%=mod;
return t;
}
|
1
2
3
4
5
| ans.a[1][1]=a2,ans.a[1][2]=a1;
base.a[1][2]=1;
base.a[2][1]=q;
base.a[1][1]=p;
ksm(n-2);
|
关于矩阵乘法的优化
A.缓存优化
先普及一点知识: $CPU\space cache$
通俗点说就是平时说的缓存,是位于$CPU$和内存之间的临时存储器,具有体积小,交换速率快的特点,存储的是$CPU$即将访问的内存.
所以缓存存在的意义就是为了加快内存访问的速度.
那么对于$OIer$来说,这东西唯一的用处就是卡常,可能会有人听过”数组不要开偶偶数大小”之类的玄学. 但这可能真的是有用的.
程序在一段时间内访问的数据通常具有局部性,比如对一维数组来说,访问了地址x上的元素,那么以后访问地址$x+1$、$x+2$上元素的可能性就比较高;这也称为$cache$的空间局限性.
如果说人话的话. 就是数组的访问顺序是水平连续的.
让我们再来两个栗子
- 1
1
2
3
4
| for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)
for(int k=1;k<=n;++k)
c[i][j]=a[i][k]*b[k][j];
|
- 2
1
2
3
4
| for(int i=1;i<=n;++i)
for(int k=1;k<=n;++k)
for(int j=1;j<=n;++j)
c[i][j]=a[i][k]*b[k][j];
|
眼尖的同学可能会发现,这两段程序唯一的不同只有二三层的循环循顺序啊(#`O′)(啪,就你多嘴)
那么实际上的效率可能会在数据很大的时候产生极大的差异.
因为根据我们上边所了解到的信息,对于代码2中的$a[i]$和$b[k]$这两行的访问都是连续的,所以缓存会被充分利用. 这样就达到了卡常的目的.
这种做法的术语是$loop\space permutation$(循环置换)
测试代码(搬运的时候图片丢了,凑合着看吧)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| #include<stack>
#include<ctime>
#include<cmath>
#include<queue>
#include<string>
#include<vector>
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#define file(a) freopen(a".in","r",stdin);freopen(a".out","w",stdout);
using namespace std;
char IN[1<<17],*SS=IN,*TT=IN;
inline char gc(){return (SS==TT&&(TT=(SS=IN)+fread(IN,1,1<<17,stdin),SS==TT)?EOF:*SS++);}
inline int read()
{
int now=0,f=1;register char c=gc();
for(;!isdigit(c);c=='-'&&(f=-1),c=gc());
for(;isdigit(c);now=now*10+c-'0',c=gc());
return now*f;
}
const int mod=1e9+7;
long long a[1100][1100];
long long temp[1010][1010];
long long b[1010][1010];
long long c[1010][1010];
int main()
{
freopen("a.out","r",stdin);
freopen("x1.out","w",stdout);
int n=read();
for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)b[i][j]=read();
for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)c[i][j]=read();
for(int i=1;i<=n;++i)
for(int k=1;k<=n;++k)
for(int j=1;j<=n;++j)
(a[i][j]+=b[i][k]*c[k][j])%=mod;
for(int i=1;i<=n;++i)printf("%lld ",a[5][i]);
printf("\n");
printf("Elapsed time:%.2lf secs.\n",1.0*clock()/1000.0);
return 0;
}
|
有兴趣的同学可以去尝试做一下$HUD4920$.
经典的矩阵乘法卡$(du)$常$(liu)$题.
B.矩阵分块
当矩阵特别大时,可能会发生缓存放不下的情况,那么之前的$ikj$优化就会收效甚微,所以我们考虑把一个矩阵分为几块子矩阵,不过需要注意的是A的行的划分与B的列的划分必须一致.
1
2
3
4
5
6
7
8
| int size=n/25;
for(int it=1;it<=n;it+=size)
for(int jt=1;jt<=n;jt+=size)
for(int kt=1;kt<=n;kt+=size)
for(int i=it;i<=it+size;i++)
for(int j=jt;j<=jt+size;j++)
for(int k=kt;k<=kt+size;k++)
(a[i][j]+=b[i][k]*c[k][j])%=mod;
|
C.次数优化
大家可能做过最优矩阵链乘问题问题.
本质就是利用结合律来减少乘法次数.
例如
A是一个$50×10$的矩阵,B是$10×20$的矩阵,C是$20×5$的矩阵
那么要把$ABC$乘起来的话,有两种顺序,一种是$(A(BC))$,另一种是$((AB)C)$
而这两种顺序的乘法次数一个是$3500$次,而另一个却是$15000$次,所以当数据非常大的时候,我们可以考虑构造一个乘法的顺序,使得乘法次数最小,但只适用于矩阵少而大的情况.
D.取模优化
众所周知,计算机中的取模运算非常之慢,而$long\space long$的取模是最慢的,所以很多人程序的常数大的原因也是这个. 所以我们可能会在某些人的程序中看到这样的函数
1
| ll mo(ll x,ll y){return x+y>=mod?x+y-mod:x+y;}
|
这就是利用减法代替取模从而达到卡常的效果.
对于矩阵乘法也是这样. 我们可以设定一个$ull$上界$Q=16ull*mod$,当超过这个上界时就可以直接用减法代替取模,因为当$mod$在$10^9$级别时,$ull$最多只能存下$16$个$mod\times mod$相加.
当然中间过程需要$long\space long$来存储,而最后的结果最好还是$int$类型.
所以取模次数由$O(n^3)$降到$O(n^2)$次
但实际效果略逊于$ikj$,可能是本机的问题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
| #include<stack>
#include<ctime>
#include<cmath>
#include<queue>
#include<string>
#include<vector>
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#define file(a) freopen(a".in","r",stdin);freopen(a".out","w",stdout);
using namespace std;
char IN[1<<17],*SS=IN,*TT=IN;
inline char gc(){return (SS==TT&&(TT=(SS=IN)+fread(IN,1,1<<17,stdin),SS==TT)?EOF:*SS++);}
inline int read()
{
int now=0,f=1;register char c=gc();
for(;!isdigit(c);c=='-'&&(f=-1),c=gc());
for(;isdigit(c);now=now*10+c-'0',c=gc());
return now*f;
}
const int maxn=100005;
typedef unsigned long long ull;
const int mod=1e9+7;
const ull Q=16ull*mod*mod;
int a[1100][1100];
long long temp;
ull b[1010][1010];
ull c[1010][1010];
ull mo(ull x,ull y){return x+y>=Q?x+y-Q:x+y;}
int main()
{
freopen("a.out","r",stdin);
freopen("x2.out","w",stdout);
int n=read();
for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)b[i][j]=read();
for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)c[i][j]=read();
for(int i=1;i<=n;++i)
for(int j=1;j<=n;++j)
{
temp=0;
for(int k=1,s=1;k<=n;++k,s++)
{
if(s==16)temp=mo(temp,b[i][k]*c[k][j]),s=1;
else temp+=b[i][k]*c[k][j];
}
a[i][j]=temp%mod;
}
for(int i=1;i<=n;++i)printf("%d ",a[5][i]);
printf("\n");
printf("Elapsed time:%.2lf secs.\n",1.0*clock()/1000.0);
return 0;
}
|
和$ikj$优化一起用的效果
![]()
E.特判优化
特判矩阵的元素是否为$0$,如果是$0$可以直接$continue$,在稀疏矩阵里有奇效,由于数据比较难生成,所以不实际运行.还请见谅
感谢审核的$@ComeIntoPower$提出的宝贵意见.
另:测试数据均为以下代码生成
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| #include<stack>
#include<ctime>
#include<cmath>
#include<queue>
#include<string>
#include<vector>
#include<cstdio>
#include<cstring>
#include<iostream>
#include<algorithm>
#define file(a) freopen(a".in","r",stdin);freopen(a".out","w",stdout);
using namespace std;
char IN[1<<17],*SS=IN,*TT=IN;
inline char gc(){return (SS==TT&&(TT=(SS=IN)+fread(IN,1,1<<17,stdin),SS==TT)?EOF:*SS++);}
inline int read()
{
int now=0,f=1;register char c=gc();
for(;!isdigit(c);c=='-'&&(f=-1),c=gc());
for(;isdigit(c);now=now*10+c-'0',c=gc());
return now*f;
}
const int maxn=100005;
int main()
{
srand(time(NULL)*20020307%19260817);
freopen("a.out","w",stdout);
int n=1000;
printf("1000\n");
for(int i=1;i<=n;++i)
{
for(int j=1;j<=n;++j)
printf("%d ",rand()*10+50000);
printf("\n");
}
for(int i=1;i<=n;++i)
{
for(int j=1;j<=n;++j)
printf("%d ",rand()*10+50000);
printf("\n");
}
return 0;
}
|
转载自此文章https://shehuizhuyihao.blog.luogu.org/post-zhen-sheng-fa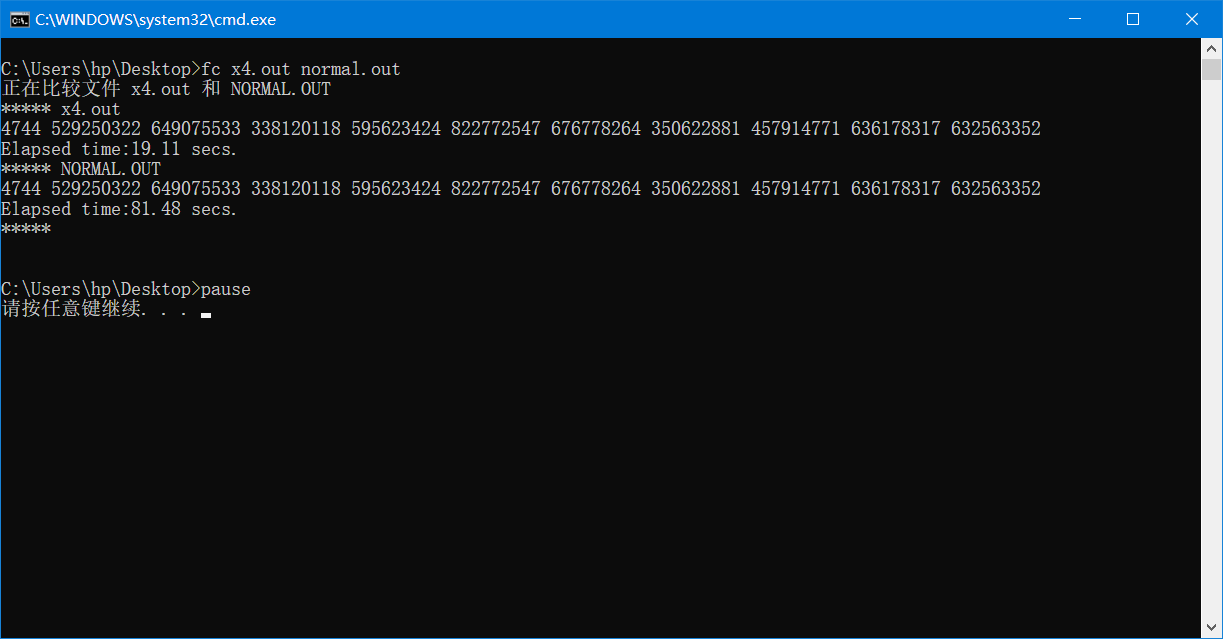
评论